Qual a Relação de Hábitos de Vida e Fatores Socioeconômicos com o Diagnóstico de Câncer de Próstata no Brasil?
What is the Relation of Lifestyle Habits and Socioeconomic Factors with Prostate Cancer Diagnosis in Brazil?
¿Cuál es la Relación de los Hábitos de Vida y los Factores Socioeconómicos con el Diagnóstico de Cáncer de Próstata en el Brasil?
https://doi.org/10.32635/2176-9745.RBC.2024v70n2.4633
Marco Antonio de Souza1; Camila Nascimento Monteiro2; Cláudia Renata dos Santos Barros3
1Universidade de São Paulo, Instituto de Física. São Paulo (SP), Brasil. E-mail: marsouza@if.usp.br. Orcid iD: https://orcid.org/0000-0003-3340-5912
2Hospital Sírio-Libanês, Saúde Populacional. São Paulo (SP), Brasil. E-mail: c.nascimentomonteiro@gmail.com. Orcid iD: https://orcid.org/0000-0002-0121-0398
3Instituto Butantan. São Paulo (SP), Brasil. E-mail: barros.crs3@gmail.com. Orcid iD: https://orcid.org/0000-0002-1582-2010
Endereço para correspondência: Marco Antonio de Souza. Rua Manuel Jacinto, 667 – bloco 9, apto. 73 – Vila Morse. São Paulo (SP), Brasil. CEP 05624-001 E-mail: marsouza@if.usp.br
RESUMO
Introdução: O câncer de próstata é o segundo mais comum entre os homens no Brasil, atrás apenas do câncer de pele não melanoma. Atualmente, há interesse em analisar dados referentes ao câncer com métodos do tipo machine learning. Objetivo: Investigar as características físicas, socioeconômicas e de hábitos de vida que podem estar associadas ao diagnóstico de câncer de próstata no Brasil. Método: Uma base de microdados referente à Pesquisa Nacional de Saúde 2019 foi utilizada, com a seleção de 42.799 indivíduos do sexo masculino; esse grupo foi analisado por meio de métodos estatísticos e modelagem por machine learning (regressão logística e árvore de decisão). Resultados: Os modelos aplicados permitiram identificar com bom nível de acurácia (próximo ou acima de 80%) os indivíduos que receberam o diagnóstico de câncer de próstata (DCP), além de grupos com características específicas mais fortemente associadas a essa doença. Entre as variáveis mais significativamente ligadas à taxa de DCP, destacam-se: idade, diagnóstico de alto nível de colesterol, se possui plano de saúde e nível de instrução. Conclusão: Os modelos indicam um nível de associação significativo de fatores socioeconômicos, físicos e alimentares com a frequência de DCP no grupo analisado. O alto nível de acurácia e a sensibilidade dos modelos demonstram o potencial dos métodos de machine learning para a previsão de DCP.
Palavras-chave: Neoplasias da Próstata; Estilo de vida/etnologia; Estudos Transversais; Aprendizado de Máquina.
ABSTRACT
Introduction: Prostate cancer is the second most common cancer among men in Brazil, behind only non-melanoma skin cancer. Currently, there is interest in analyzing data related to cancer with machine learning type methods. Objective: The investigation of physical, lifestyle and socioeconomic features that may be associated with prostate cancer diagnosis in Brazil. Method: A microdata base referring to the 2019 National Health Survey in Brazil was utilized, and 42,799 male individuals were selected; this group was analyzed through statistical methods and machine learning modeling (logistic regression and decision tree). Results: The models applied allowed to identify with a good level of accuracy (near or above 80%) individuals with diagnosis of prostate cancer (DPC), in addition to groups with specific features more strongly associated with this disease. Among the variables more significantly associated with DPC rate, the following stand out: age, diagnosis of high level of cholesterol, health insurance, and level of education. Conclusion: The models indicate a significant level of association of socioeconomic, physical, and dietary factors with the frequency of DPC in the group analyzed. The high level of accuracy and sensitivity of the models demonstrates the potential of machine learning methods for predicting DPC.
Key words: Prostatic Neoplasms; Life Style/ethnology; Cross-Sectional Studies; Machine Learning.
RESUMEN
Introducción: El cáncer de próstata es el segundo cáncer más común entre los hombres en el Brasil, sólo detrás del cáncer de piel no melanoma. Actualmente existe interés en analizar datos relacionados con el cáncer con métodos de tipo machine learning. Objetivo: Investigar características físicas, de estilo de vida y socioeconómicas que pueden estar asociadas con el diagnóstico de cáncer de próstata en el Brasil. Método: Se utilizó una base de microdatos referente a la Encuesta Nacional de Salud de 2019, con la selección de 42 799 individuos de sexo masculino; este grupo fue analizado mediante métodos estadísticos y modelado de machine learning (regresión logística y árbol de decisión). Resultados: Los modelos aplicados permitieron identificar con buen nivel de exactitud (cerca o por encima del 80%) a los individuos con diagnóstico de cáncer de próstata (DCP), además de grupos con características específicas más fuertemente asociadas a esta enfermedad. Entre las variables más significativamente asociadas a la tasa de DCP destacan las siguientes: la edad, el diagnóstico de nivel alto de colesterol, si se tiene seguro médico y el nivel de educación. Conclusión: Los modelos indican un nivel significativo de asociación de factores socioeconómicos, físicos y dietéticos con la frecuencia de DCP en el grupo analizado. El alto nivel de exactitud y sensibilidad de los modelos demuestra el potencial de los métodos de machine learning para predecir la DCP.
Palabras clave: Neoplasias de la Próstata; Estilo de Vida/etnología; Estudios Transversales; Aprendizaje Automático.
INTRODUÇÃO
No Brasil, o câncer de próstata é o segundo mais comum entre os homens1. Em países como Estados Unidos, há uma estimativa de um em cada oito homens com câncer de próstata no decorrer da vida2. Esse tipo de câncer é multicausal e os principais fatores de risco identificados são idade, cor/etnia, nacionalidade, histórico familiar e alterações genéticas. Há também outros fatores associados ao hábito de vida relacionados ao câncer de próstata que têm sido estudados para melhor conhecimento de possível relação causal, entre eles: dieta, obesidade, tabagismo, exposição ocupacional, inflamação da próstata e doenças sexualmente transmissíveis3. Além disso, fatores sociais e econômicos têm uma forte influência sobre os hábitos de vida da população e as suas condições de acesso aos serviços de saúde, podendo, em tese, influenciar a ocorrência e o diagnóstico de câncer de próstata (DCP) na população masculina.
Estudos anteriores já foram publicados sobre o câncer de próstata no Brasil nos aspectos de saúde pública e epidemiologia. Por exemplo, há estudos de revisão da literatura sobre o tema com uma contextualização para a saúde pública no Brasil4,5, outros que caracterizam os indivíduos com a doença ou o estadiamento da doença por meio de variáveis clínicas e sociodemográficas6,7, discussões sobre a forma de rastreamento populacional do câncer de próstata8, e estudos sobre a tendência temporal da mortalidade por câncer de próstata no Brasil ou regiões específicas do país9-11.
Nos últimos anos, há um interesse crescente pelo uso de métodos de machine learning ou inteligência artificial (IA) para a pesquisa e prevenção do câncer12,13, por exemplo, pela análise de diversas variáveis que podem influenciar a taxa de ocorrência de diferentes tipos de câncer, e por análise de imagens médicas. Nesse contexto, o presente estudo tem como objetivos: analisar os fatores associados ao DCP no Brasil por meio dos dados da Pesquisa Nacional de Saúde (PNS) 2019; e testar modelos preditivos de machine learning sobre o câncer de próstata com o uso desses dados.
MÉTODO
Trata-se de um estudo transversal com dados secundários provenientes da PNS realizada em 2019. A base de dados contém 42.799 indivíduos; destes, 339 (0,79%) disseram “ter recebido” DCP em algum momento da sua vida e 42.460 (99,21%) “não ter recebido”.
Entre as 58 variáveis selecionadas inicialmente, estava a variável dependente “câncer de próstata”: ter recebido o diagnóstico ou não ter recebido (sim ou não); e 57 eram variáveis independentes.
Após a aplicação de critérios de eliminação de variáveis que serão explicados nessa seção, restaram 13 variáveis independentes, as quais foram aplicadas nos modelos preditivos. São elas: idade; há quantos anos a pessoa consultou um médico pela última vez; como a pessoa avalia a sua própria saúde (muito boa, boa, ruim etc.); quantos dias da semana consome frutas; quantos dias da semana consome verduras e/ou legumes; quantos dias da semana consome sucos artificiais; se já recebeu diagnóstico de nível alto de colesterol (sim ou não); se manuseia ou manuseava substâncias químicas no trabalho que são potencialmente prejudiciais à saúde (sim ou não); se possui plano de saúde (sim ou não); cor/etnia (branca, preta, parda etc.); nível de instrução (fundamental completo, médio completo, superior incompleto etc.); se fuma algum produto do tabaco, e com qual frequência (não fuma, diariamente, menos que diariamente); e se já recebeu diagnóstico de depressão (sim ou não).
A base original foi obtida no site do Instituto Brasileiro de Geografia e Estatística (IBGE), na seção da PNS, subseção de microdados14. Essa pesquisa, inquérito domiciliar de saúde, foi realizada em 2019, com amostra representativa da população brasileira. A base original, contida no arquivo PNS_2019.txt, possui 346 Mb, um total de 279.382 linhas (indivíduos entrevistados) e 817 colunas (características).
A PNS teve aprovação da Comissão Nacional de Ética em Pesquisa (Conep) em agosto de 2019 sob o número n.º 3.529.376 (CAAE: 11713319.7.0000.0008) para a edição de 2019. Como esta pesquisa utilizou dados disponibilizados publicamente, justifica-se que, para o presente estudo, não há necessidade de análise pelo Comitê de Ética em Pesquisa (CEP), de acordo com a Resolução n.º 510/201615 do Conselho Nacional de Saúde (CNS).
No primeiro processo de filtragem, feito pela biblioteca PNS-IBGE14 do R16, foi possível extrair um dataframe da base original com as variáveis de interesse. Foi, então, extraído um arquivo csv de 279.382 linhas (indivíduos entrevistados) e 68 colunas (características). No segundo processo de filtragem, a base de dados foi reduzida para conter apenas os indivíduos do sexo masculino que responderam duas perguntas que compõem a variável dependente: a) se o indivíduo recebeu diagnóstico de algum tipo de câncer na vida (1 = sim, 2 = não); b) se o indivíduo recebeu DCP ao longo da vida (1 = sim, 2 = não). Após o 2º processo de filtragem, foi obtido um dataframe de 42.799 linhas (indivíduos) e 58 colunas (características). A base de dados então foi devidamente preparada para ser usada nas modelagens, incluindo o tratamento de dados faltantes (missings) e a organização de variáveis categóricas, resultando em uma base de dados final com 42.799 linhas (indivíduos) e 58 variáveis.
Com a base de dados devidamente preparada, foram realizados os procedimentos de filtragem das variáveis de maior relevância, análise estatística e modelagem por métodos de machine learning. No caso deste trabalho, os modelos de classificação escolhidos para a descrição da variável dependente "DCP" foram: regressão logística e árvore de decisão. Tais procedimentos são detalhados a seguir.
Antes da aplicação da base de dados nos modelos de regressão logística e árvore de decisão, foi feita uma filtragem inicial das variáveis descritivas via information value (IV), calculado pelo RStudio17. Todas as variáveis com IV considerado fraquíssimo (≤ 0,02) foram excluídas dos modelos previamente, restando 42 variáveis descritivas nessa etapa.
Após filtragem pelo IV, foi aplicado o modelo de regressão logística com o uso do RStudio17, considerando como variável dependente o DCP (variável binária, com 1 para “sim”, e 0 para “não”). Para isso, a base de dados foi dividida em base de treino (70% dos indivíduos) e base de teste (30%). A divisão da base de dados em treino e teste é importante para realizar a validação cruzada do modelo. Portanto, o modelo é todo desenvolvido (ou parametrizado) com a base de treino, e, em seguida, validado na base de teste mediante métricas como a acurácia, sensibilidade e especificidade. O modelo de regressão logística permite prever se a variável dependente terá resultado positivo ou negativo para um certo indivíduo da base.
Usando a base de treino, foi aplicado o método backward e um nível de significância de 0,10 (ou seja, p ≤ 0,10) para a seleção das variáveis. Após esse processo, chegou-se a um modelo final com um total de 13 variáveis descritivas, todas categóricas, as quais foram citadas antecipadamente no método.
O modelo de árvore de decisão foi executado no RStudio17, com as mesmas 13 variáveis descritivas, considerando árvores de 2 e 3 níveis. A árvore de decisão também é utilizada como um modelo preditivo para a variável dependente DCP, e, além disso, permite identificar grupos específicos com maior frequência de casos positivos para a variável dependente, de acordo com o nível de associação com as variáveis descritivas.
RESULTADOS
Entre as variáveis descritivas selecionadas, a que apresentou o valor mais alto de IV foi a variável “idade” (IV = 2,86), o que representa uma capacidade preditiva muito forte em relação ao câncer de próstata. Verifica-se que a idade média dos homens entrevistados é de 45,9 anos e a mediana é de 45 anos; isso mostra que o grupo de 50% dos indivíduos acima da mediana contém a faixa etária de maior propensão a receber DCP (Figura 1). Observando o Gráfico 1(c), nota-se que a mediana de idade dos homens que responderam “sim” para DCP (72 anos) está bem acima da mediana dos homens que responderam “não” (44 anos).
A Tabela 1 mostra a distribuição dos indivíduos nas categorias das variáveis descritivas e o cruzamento com a variável dependente DCP; os resultados que podem ser contextualizados mais claramente são:
Idade: aumento da frequência de DCP a partir de 50 anos de idade, com frequência mais alta na categoria “≥ 80 anos”.
Consultas médicas: maior frequência de DCP nos indivíduos que tiveram sua última consulta médica mais próxima do momento da pesquisa (até dois anos antes).
Autoavaliação de saúde: maior frequência de DCP nos indivíduos que afirmaram ter uma qualidade de saúde “ruim ou muito ruim”.
Diagnóstico de colesterol alto: maior frequência de DCP nos indivíduos que receberam diagnóstico de nível alto de colesterol.
Plano de saúde: maior frequência de DCP nos indivíduos que afirmam ter plano de saúde.
Diagnóstico de depressão: maior frequência de DCP nos indivíduos que receberam diagnóstico de depressão.
A seleção de variáveis descritivas como “plano de saúde” e “nível de instrução” indica uma influência da situação socioeconômica nos modelos preditivos. De fato, tal indicação pode ser verificada pelo cruzamento da variável dependente DCP com a renda familiar per capita dos indivíduos. Considerando a faixa de idade a partir de 50 anos, observam-se taxas de DCP de 0,84%, 1,82%, 2,49% e 3,07% para as respectivas faixas de renda familiar per capita (em salários-mínimos – SM): até ½ SM; mais de ½ SM até 2 SM; mais de 2 SM até 5 SM; mais de 5 SM. Isto é, a faixa de renda mais alta (mais de 5 SM) tem uma taxa de DCP ≈ 3,7 × maior do que na faixa de renda mais baixa (até ½ SM).
Com a premissa descrita acima, o possível efeito socioeconômico sobre as variáveis descritivas foi investigado; para isso, foi determinado o nível de associação entre cada variável descritiva e a renda familiar per capita pelas medidas V de Cramer e ω de Cohen. Verificou-se um nível alto de associação da renda familiar per capita com as variáveis “plano de saúde” (V de Cramer = 0,487 e ω de Cohen = 0,487) e “nível de instrução” (V de Cramer = 0,314 e ω de Cohen = 0,544). Um nível médio de associação com a renda familiar per capita foi observado na variável “cor/etnia” (V de Cramer = 0,150 e ω de Cohen = 0,260), e um nível razoável foi observado em “consumo de frutas” e “consumo de verduras e legumes” (ω de Cohen = 0,218 e 0,229, respectivamente). Portanto, a influência da renda familiar nas variáveis descritivas deve ser levada em conta na interpretação dos resultados da Tabela 1.
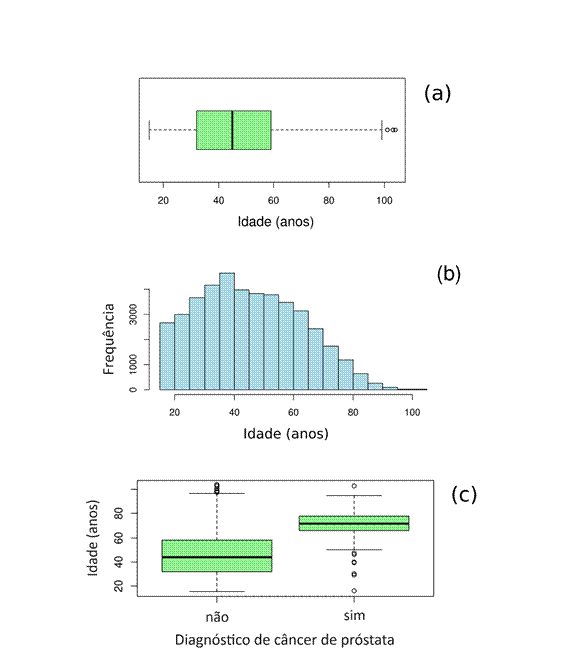
Figura 1. Descrição da variável “idade” dos indivíduos do sexo masculino selecionados na base da Pesquisa Nacional de Saúde (PNS). (a) Boxplot mostrando a distribuição de idade. (b) Histograma mostrando a distribuição de idade. (c) Comparação em boxplot das distribuições de idade nos grupos: com diagnóstico de câncer de próstata em algum momento da vida (sim); sem diagnóstico de câncer de próstata (não)
Tabela 1. Variáveis descritivas usadas nos modelos finais de regressão logística e árvore de decisão. São mostradas as categorias de cada variável, a frequência de indivíduos em cada categoria, e a frequência de casos positivos (sim) e negativos (não) de câncer de próstata em cada categoria. N.A.: pergunta não aplicada
|
Variável descritiva |
|
|
Câncer de próstata (%) |
|
|
Idade |
Faixa de idade (anos) |
Frequência (%) |
Não |
Sim |
|
< 35 |
29,46 |
99,98 |
0,02 |
|
|
≥ 35 e < 50 |
29,45 |
99,96 |
0,04 |
|
|
≥ 50 e < 65 |
24,76 |
99,35 |
0,65 |
|
|
≥ 65 e < 80 |
13,50 |
96,63 |
3,37 |
|
|
≥ 80 |
2,83 |
94,48 |
5,52 |
|
|
|
|
|
|
|
|
Consultas médicas |
Tempo desde a última consulta médica (anos) |
Frequência (%) |
Não |
Sim |
|
até 2 anos |
83,02 |
99,05 |
0,95 |
|
|
mais de 2 anos |
15,77 |
99,96 |
0,04 |
|
|
nunca foi |
1,21 |
100,00 |
0,00 |
|
|
|
|
|
|
|
|
Autoavaliação de saúde |
Autoavaliação |
Frequência (%) |
Não |
Sim |
|
muito boa ou boa |
66,77 |
99,54 |
0,46 |
|
|
regular |
27,82 |
98,58 |
1,42 |
|
|
ruim ou muito ruim |
5,41 |
98,36 |
1,64 |
|
|
|
|
|
|
|
|
Consumo de frutas |
Consumo semanal |
Frequência (%) |
Não |
Sim |
|
1 a 3 dias |
40,45 |
99,53 |
0,47 |
|
|
4 a 6 dias |
20,61 |
99,29 |
0,71 |
|
|
nunca ou muito pouco |
13,10 |
99,48 |
0,52 |
|
|
todos os dias |
25,84 |
98,50 |
1,50 |
|
|
|
|
|
|
|
|
Consumo de suco artificial a |
Consumo semanal |
Frequência (%) |
Não |
Sim |
|
1 a 3 dias |
21,37 |
99,68 |
0,32 |
|
|
4 a 6 dias |
7,89 |
99,62 |
0,38 |
|
|
nunca ou muito pouco |
64,08 |
99,00 |
1,00 |
|
|
todos os dias |
6,66 |
99,16 |
0,84 |
|
|
|
|
|
|
|
|
Diagnóstico de colesterol alto |
Resposta |
Frequência (%) |
Não |
Sim |
|
não ou N.A. |
89,12 |
99,35 |
0,65 |
|
|
sim |
10,88 |
98,02 |
1,98 |
|
|
|
|
|
|
|
|
Exposição a produtos químicos no trabalho b |
Resposta |
Frequência (%) |
Não |
Sim |
|
não ou N.A. |
87,21 |
99,12 |
0,88 |
|
|
sim |
12,79 |
99,82 |
0,18 |
|
Tabela 1. (continuação)
|
Variável descritiva |
|
|
Câncer de próstata – frequência na categoria (%) |
|
|
Possui plano de saúde |
Resposta |
Frequência (%) |
Não |
Sim |
|
não |
78,82 |
99,38 |
0,62 |
|
|
sim |
21,18 |
98,58 |
1,42 |
|
|
|
|
|
|
|
|
Cor/etnia |
Cor/etnia |
Frequência (%) |
Não |
Sim |
|
amarela |
0,73 |
98,72 |
1,28 |
|
|
branca |
36,14 |
98,89 |
1,11 |
|
|
ignorado |
0,02 |
100,00 |
0,00 |
|
|
indígena |
0,78 |
100,00 |
0,00 |
|
|
parda |
50,51 |
99,45 |
0,55 |
|
|
preta |
11,82 |
99,11 |
0,89 |
|
|
|
|
|
|
|
|
Nível de instrução |
Nível de instrução |
Frequência (%) |
Não |
Sim |
|
sem instrução ou fundamental incompleto |
42,67 |
99,03 |
0,97 |
|
|
fundamental completo ou médio incompleto |
15,48 |
99,41 |
0,59 |
|
|
médio completo ou superior incompleto |
28,93 |
99,43 |
0,57 |
|
|
superior completo |
12,92 |
99,06 |
0,94 |
|
|
|
|
|
|
|
|
Consumo de verduras e legumes |
Consumo semanal |
Frequência (%) |
Não |
Sim |
|
1 a 3 dias |
35,67 |
99,34 |
0,66 |
|
|
4 a 6 dias |
21,24 |
99,21 |
0,79 |
|
|
nunca ou muito pouco |
9,54 |
99,46 |
0,54 |
|
|
todos os dias |
33,55 |
98,99 |
1,01 |
|
|
|
|
|
|
|
|
Fuma atualmente |
Uso semanal |
Frequência (%) |
Não |
Sim |
|
diariamente |
14,32 |
99,45 |
0,55 |
|
|
menos que diário |
1,75 |
99,73 |
0,27 |
|
|
não fuma |
83,93 |
99,16 |
0,84 |
|
|
|
|
|
|
|
|
Teve diagnóstico de depressão |
Resposta |
Frequência (%) |
Não |
Sim |
|
não |
95,43 |
99,24 |
0,76 |
|
|
sim |
4,57 |
98,46 |
1,54 |
|
a De acordo com a Pesquisa Nacional de Saúde (PNS), essa variável refere-se ao consumo dos chamados sucos de “caixinha”, em lata ou refresco em pó.
b De acordo com a PNS, essa variável refere-se ao manuseio de produtos químicos como: agrotóxicos, gasolina, diesel, formol, chumbo, mercúrio, cromo, quimioterápicos etc.
Os resultados de acurácia, sensibilidade, especificidade e ROC-AUC para a regressão logística são mostrados na Tabela 2, referentes às bases de treino e teste. Observa-se que a acurácia, sensibilidade e especificidade para essas bases são muito satisfatórias, pois todas estão acima de 80%. Na base de teste, houve um pequeno aumento na acurácia e especificidade, e uma pequena diminuição na sensibilidade. O resultado obtido para o ROC-AUC na base de treino (0,822) também pode ser considerado muito satisfatório, enquanto o resultado na base de teste (0,780) encontra-se muito próximo da mesma condição.
Tabela 2. Acurácia, sensibilidade, especificidade e ROC-AUC obtidos nos modelos de regressão logística, árvore de decisão de 2 níveis e árvore de decisão de 3 níveis, considerando as bases de treino (70% do total) e teste (30% do total)
|
Modelo |
Base |
Acurácia |
Sensibilidade |
Especificidade |
ROC-AUC |
|
Regressão logística |
treino |
0,828 |
0,828 |
0,828 |
0,822 |
|
teste |
0,835 |
0,802 |
0,835 |
0,780 |
|
|
Árvore de decisão (2 níveis) |
treino |
0,801 |
0,850 |
0,800 |
0,823 |
|
teste |
0,805 |
0,821 |
0,804 |
0,812 |
|
|
Árvore de decisão (3 níveis) |
treino |
0,767 |
0,906 |
0,766 |
0,832 |
|
teste |
0,773 |
0,887 |
0,772 |
0,813 |
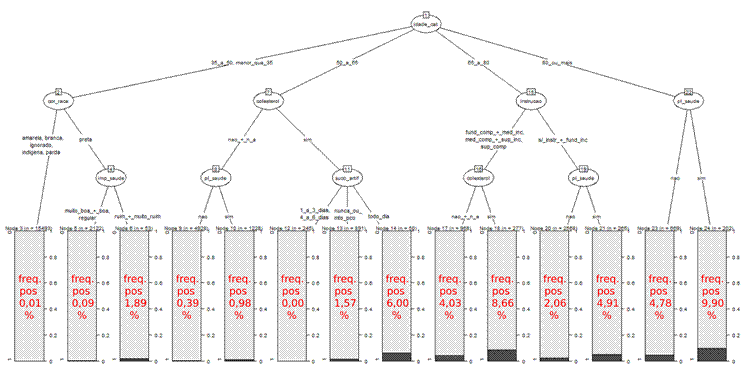
Os resultados obtidos para as árvores de decisão de 2 e 3 níveis são mostrados graficamente nas Figuras 2 e 3, respectivamente, referentes à base de treino. Observando as frequências de casos de câncer de próstata nos nós finais da árvore de 2 níveis, verifica-se:
● Os nós 3 e 4 sugerem que há uma probabilidade maior de ocorrência de câncer de próstata em homens negros comparativamente ao conjunto das outras etnias, considerando a faixa etária abaixo de 50 anos;
● Os nós 6 e 7 indicam que o grupo de homens com nível de colesterol alto tem uma maior frequência de DCP (≈ 3× maior) em comparação com o grupo de nível de colesterol normal ou desconhecido, considerando a faixa etária de 50 a 65 anos;
● Os nós 9 e 10 indicam que o grupo de homens com nível de instrução entre o ensino fundamental completo e superior completo tem uma maior frequência de DCP (≈ 2× maior) em comparação com o grupo de menor nível de instrução, considerando a faixa etária a partir de 65 anos e abaixo de 80 anos;
● Os nós 12 e 13 indicam que o grupo de homens que possuem plano de saúde tem uma maior frequência de DCP (≈ 2× maior) em comparação com o grupo que não possui plano de saúde, considerando a faixa etária a partir de 80 anos.
Com relação ao nó 5 (o qual resulta nos nós finais 6 e 7), pode-se avaliar o nível de associação entre o fator de risco “colesterol alto” e o desfecho DCP para o subgrupo de homens com idade a partir de 50 anos e menor que 65 anos, utilizando o odds ratio (OR). Nesse caso, foi obtido OR = 2,87 (intervalo de confiança – IC 95%: 1,58 – 5,21), representando um nível de associação significativo.
Ao interpretar os resultados dos nós 9 e 10, deve-se levar em conta a forte associação entre nível de instrução e renda familiar per capita discutida anteriormente18. A respeito dos nós 12 e 13, deve-se levar em conta as diferentes características dos sistemas público e privado de saúde no Brasil, além da forte associação entre a variável “plano de saúde” e a renda familiar per capita discutida anteriormente19.
Figura 2. Árvore de decisão de 2 níveis, considerando a base de treino com 70% dos indivíduos selecionados. As porcentagens em vermelho indicam a frequência de casos positivos de câncer de próstata nos nós finais da árvore
Legendas: idade_cat = idade na forma categórica (anos); cor_raca = cor/etnia; colesterol = nível de colesterol alto; instrucao = nível de instrução; pl_saude = plano de saúde; n_a = pergunta não aplicada; fund_comp = nível fundamental completo; med_inc = nível médio incompleto; med_comp = nível médio completo; sup_inc = nível superior incompleto; sup_comp = nível superior completo; s/_instr = sem instrução; e fund_inc = nível fundamental incompleto.